👾 读懂World Supercomputer
本文为Hyper Oracle撰写, English Version: Stanford Blockchain Review.
0. 简介
从比特币的点对点共识算法到以太坊的 EVM, 再到 Network State 的概念, 区块链社区一直以来的目标之一是构建一个世界超级计算机 (World Supercomputer). 更具体地说, 是一个去中心化、无法停止、无需信任且可扩展的统一状态机. 尽管很早就已知所有这些在理论上是可能的, 但迄今为止, 大部分正在进行的努力都非常零散, 并存在严重的权衡和限制. 在本文中, 我们将探讨现有尝试构建世界计算机所面临的一些权衡和限制, 然后分析构建这样一台机器所需的必要组成部分, 并最终提出一个新颖的世界超级计算机架构.
1. 当前方法的局限性
a) 以太坊与 L2 Rollups
以太坊是第一个真正的、可以说是最成功的构建世界超级计算机的尝试. 然而, 在整个发展过程中, 以太坊极大地优先考虑了去中心化和安全性, 而牺牲了可扩展性和性能. 因此, 虽然可靠, 普通的以太坊与世界超级计算机相去甚远 —— 它无法实现可扩展性.
目前对所有这些问题的潜在解决方案是 L2 Rollup, 它已成为增强以太坊世界计算机性能的最广泛采用的扩展解决方案. 作为在以太坊之上构建的额外层级, L2 Rollup 提供了显著的好处, 并得到了社区的支持.
尽管 L2 Rollup 有几种定义, 但普遍认同的观点是, L2 Rollup 是一个具有两个关键特征的网络, 即以太坊或其他基础网络的链上数据可用性和链下交易执行. 基本上, 历史状态或输入交易数据是公开可访问的, 并且在以太坊上进行某种承诺验证, 但所有单个交易和状态转换都发生在主网之外.
虽然 L2 Rollup 确实极大地提升了这些 “全球计算机” 的性能, 但其中许多存在中心化的系统风险, 这从根本上破坏了区块链作为去中心化网络的原则. 这是因为链下执行不仅涉及单个状态转换, 还涉及这些交易的排序或批处理. 在大多数情况下, L2 排序器 (Sequencer) 负责排序, 而 L2 验证器 (Validator) 计算新状态. 然而, 将排序权力交给 L2 排序器会带来集中化风险, 其中中心化的排序器可以滥用其权力, 任意地审查交易, 危及网络活力, 并从 MEV (最大化以太币价值) 攫取中获利.
虽然已经有很多关于降低 L2 中心化风险的讨论, 例如通过共享、外包或 Based 排序器的需要权衡的解决方案或去中心化的排序器解决方案 (例如 PoA、PoS 领导者选择、MEV 拍卖和 PoE), 但其中许多尝试仍处于概念设计阶段, 并且离解决这个问题还有很大差距. 此外, 许多 L2 项目似乎不愿意实施去中心化的排序器解决方案. 例如, Arbitrum 曾表示去中心化的排序器可能成为一个可选功能. 除了中心化排序器的问题外, L2 Rollup 还可能存在来自高硬件要求的完整节点、治理风险和应用程序 Rollup 趋势的中心化问题, 我们不会详细讨论这些问题.
b) L2 Rollup 和世界计算机的三难问题
所有这些依靠 L2 来扩展以太坊的中心化问题都暴露了一个基本问题, 即由经典区块链 "三难" 衍生出来的 "世界计算机三难":
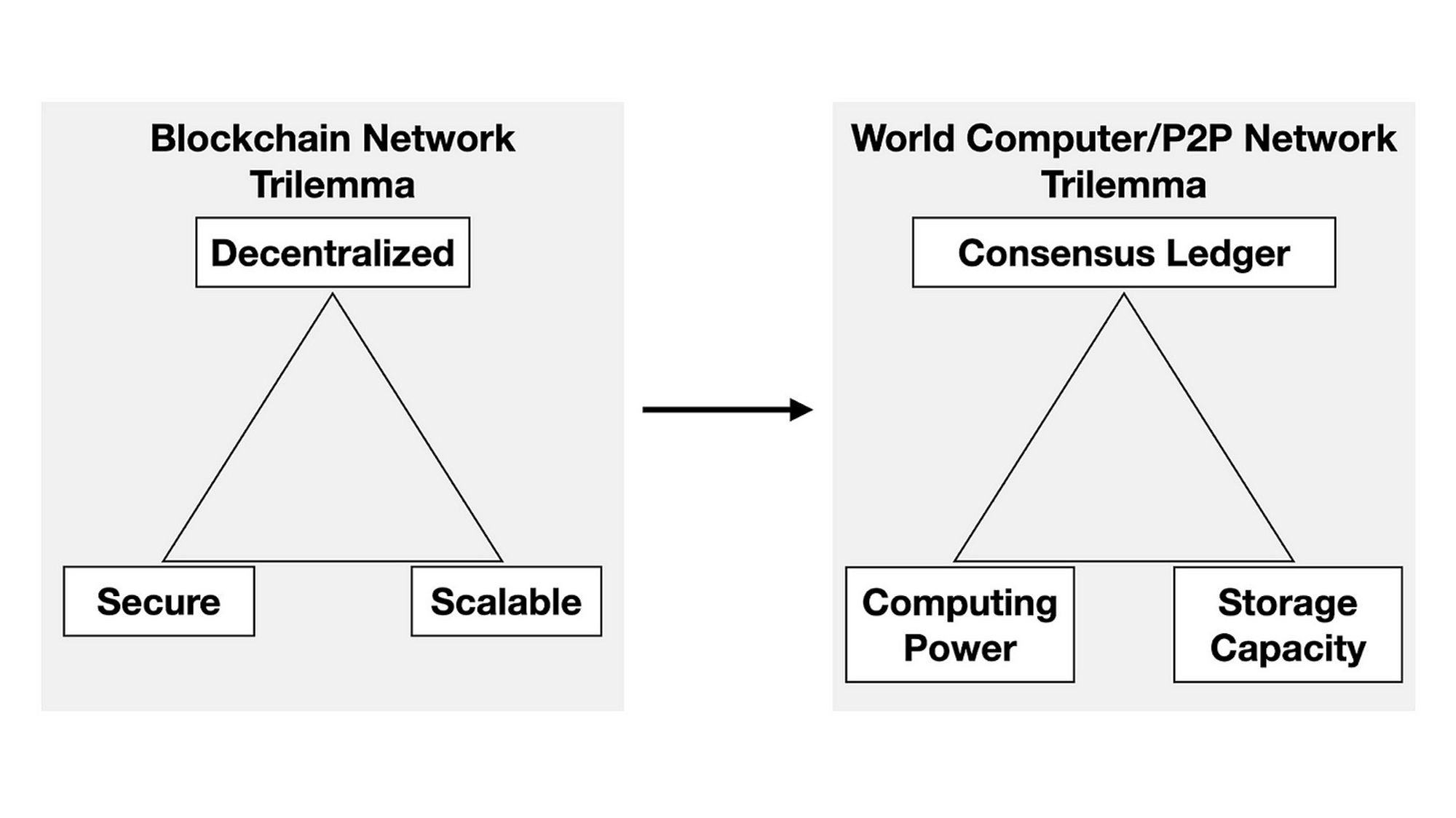
在这个三难困境中, 不同的优先级将导致不同的权衡:
- 强一致性分类账: 天然需要重复的存储和计算, 因此不适合扩展存储和计算.
- 强计算能力: 在执行大量计算和证明任务时需要重复使用共识, 因此不适合大规模存储.
- 强存储容量: 在执行频繁的随机采样空间证明时需要重复使用共识, 因此不适合计算.
传统的 L2 方案确实以模块化的方式构建了世界超级计算机. 然而, 由于不基于上述优先级对不同的功能进行分区, 即使有了扩展, 世界超级计算机仍然保持以太坊的原始大型机架构. 这种架构无法满足去中心化和性能等其他特性, 也无法解决世界超级计算机的三难困境.
换句话说, L2 Rollup 实际上实现了以下功能:
然而, L2 Rollup 并没有提供以下功能:
- 世界超级计算机的去中心化
- 世界超级计算机的性能提升 (各个 Rollup 的最大 TPS 相加实际上是不够的), 而且 L2 不能比 L1 具有更快的最终性)
- 世界超级计算机的计算 (涉及超出交易处理的计算, 如机器学习和预言机)
尽管世界超级计算机架构可以包含 L2 和模块化区块链, 但它们没有解决根本问题. L2 可以解决区块链的三难困境, 但不能解决世界超级计算机本身的三难困境. 因此, 正如我们所看到的, 目前的方法不足以真正实现以太坊最初设想的去中心化世界超级计算机. 我们需要在性能扩展和去中心化之间取得平衡, 而不是通过性能扩展逐步实现去中心化.
2. 世界超级计算机的设计目标
为此, 我们需要一个网络来解决真正的通用密集计算问题 (尤其是机器学习和预言机), 同时保持基础层区块链的完全去中心化. 此外, 我们必须确保网络能够支持高强度的计算, 例如机器学习 (ML), 可以直接在网络上运行, 并最终在区块链上得到验证. 此外, 我们需要在现有的世界超级计算机实现之上提供充足的存储和计算能力, 具有以下目标和设计方法:
a) 计算需求
为了满足世界计算机的需求和目的, 我们扩展了以太坊所描述的世界计算机的概念, 力求打造一个世界超级计算机.
世界超级计算机首先需要以去中心化的方式完成当今计算所能做的事情, 并具备额外的功能. 为了为大规模采用做准备, 开发人员需要世界超级计算机来加速去中心化机器学习的开发和采用, 以进行模型推理和验证.
大型模型, 如 MorphAI, 将能够使用以太坊来分发推理任务, 并验证任何第三方节点的输出.
在像机器学习这样计算资源密集型的任务中, 实现这样的目标不仅需要最小化信任的计算技术, 如零知识证明, 还需要在中心化网络上具备更大的数据容量. 这些是无法在单个 P2P网络 (如传统的区块链) 上实现的事情.
b) 性能瓶颈的解决方案
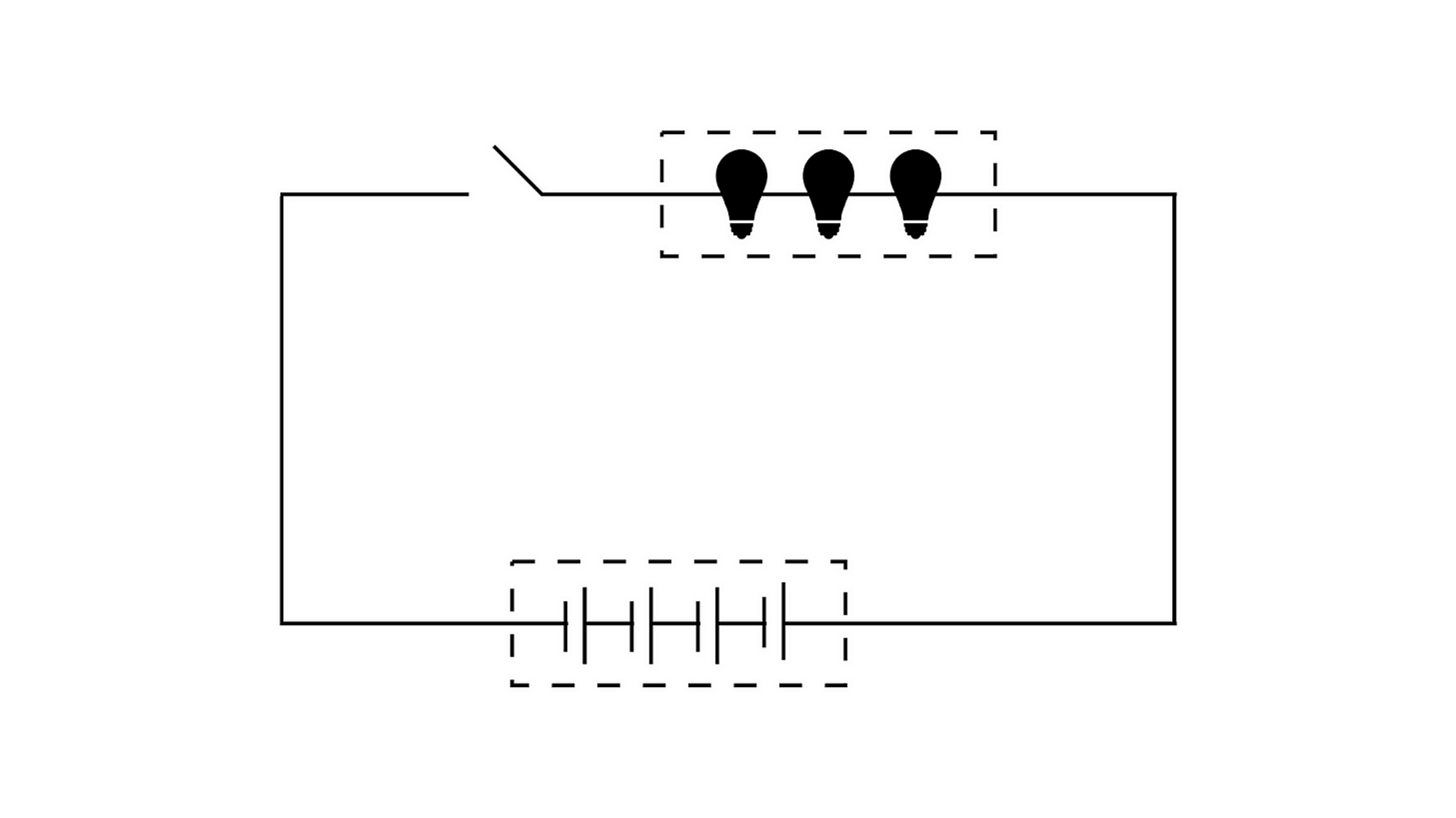
在计算机的早期发展中, 我们的先驱者们面临着类似的计算机性能瓶颈, 他们在计算能力和存储容量之间进行权衡. 以电路的最小组成部分为例来说明.
我们可以将计算量比作灯泡/晶体管的数量, 将存储容量比作电容. 在电路中, 灯泡需要电流来发光, 类似于计算任务需要计算量来执行. 而电容则存储电荷, 类似于存储可以存储数据.
对于相同的电压和电流, 灯泡和电容之间可能存在能量分配的权衡. 通常情况下, 更高的计算量需要更多的电流来执行计算任务, 因此需要较少的电容来存储能量. 较大的电容可以存储更多的能量, 但在更高的计算量下可能导致较低的计算性能. 这种权衡导致了计算和存储在某些情况下无法结合的情况.
在冯·诺伊曼计算机体系结构中, 它指导了将存储设备与中央处理器分离的概念. 类似于将灯泡与电容解耦, 这可以解决我们的世界超级计算机系统的性能瓶颈.
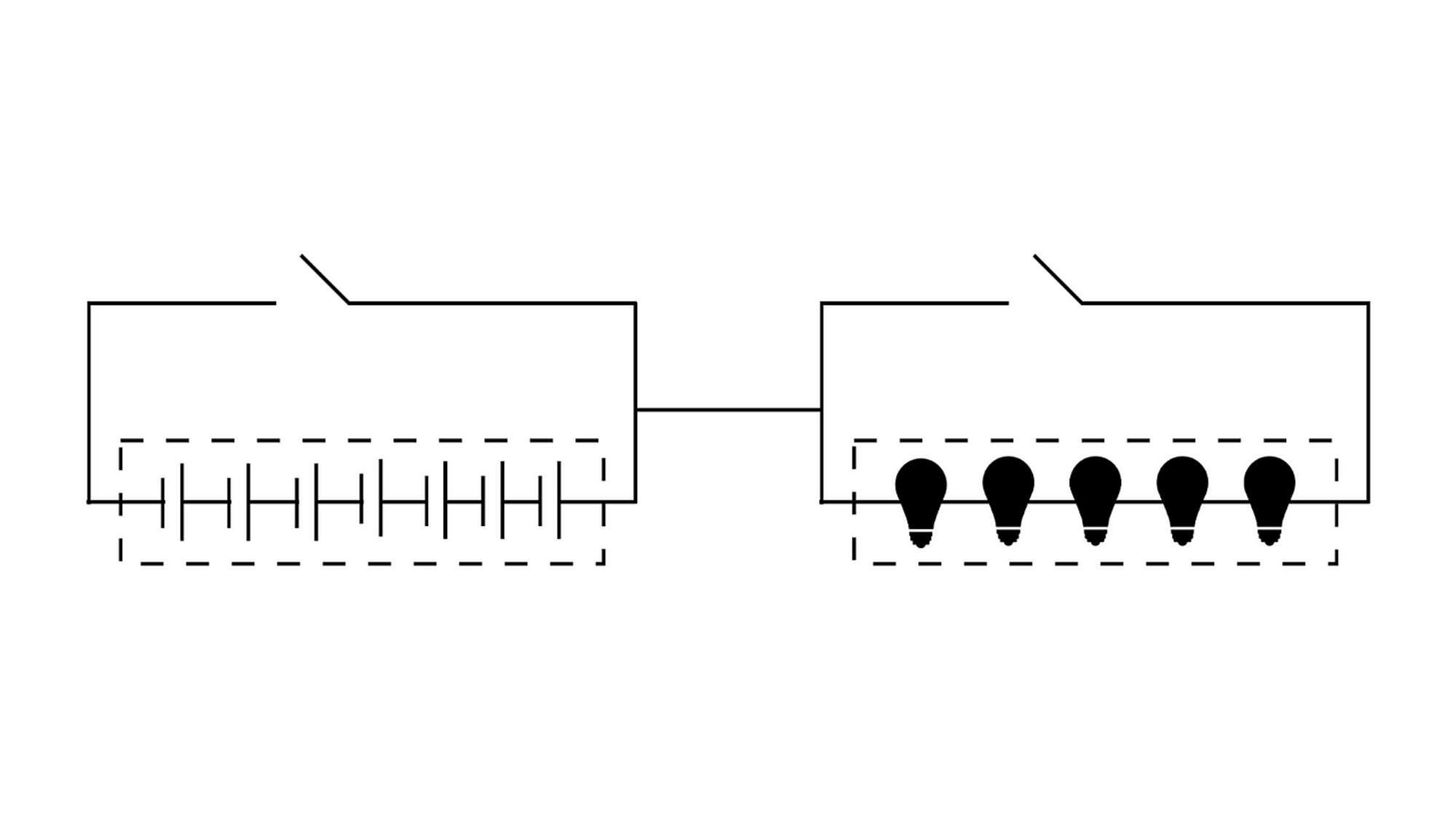
此外, 传统的高性能分布式数据库采用了将存储和计算分离的设计方案. 这个方案被采用是因为它与世界超级计算机的特性完全兼容.
c) 新颖的网络拓扑结构
模块化区块链 (包括 L2 rollups) 和世界超级计算机体系结构之间的主要区别在于它们的目的:
- 模块化区块链: 旨在通过选择模块 (共识、DA、结算和执行) 将它们组合成模块化区块链, 从而创建一个新的区块链.
- 世界超级计算机: 旨在通过将网络 (基础层区块链、存储网络、计算网络) 组合成一个世界计算机, 建立一个全球的去中心化的计算机/网络.
我们提出了一个与模块化区块链和 L2 有所不同的选择. 最终的世界超级计算机将由三个拓扑异构的 P2P 网络组成, 通过一个无信任总线 (connector), 如零知识证明技术, 进行连接: 共识账本、计算网络和存储网络. 这个基本设置使得世界超级计算机能够解决世界计算机三难问题, 并且可以根据需要添加其他组件以适应特定应用.
值得注意的是, 拓扑异构性不仅涉及到架构和结构上的差异, 还包括拓扑形式上的根本差异. 例如, 尽管以太坊和 Cosmos 在网络层和网络互联层面上是异构的, 但在拓扑异构性方面仍然是相等的.
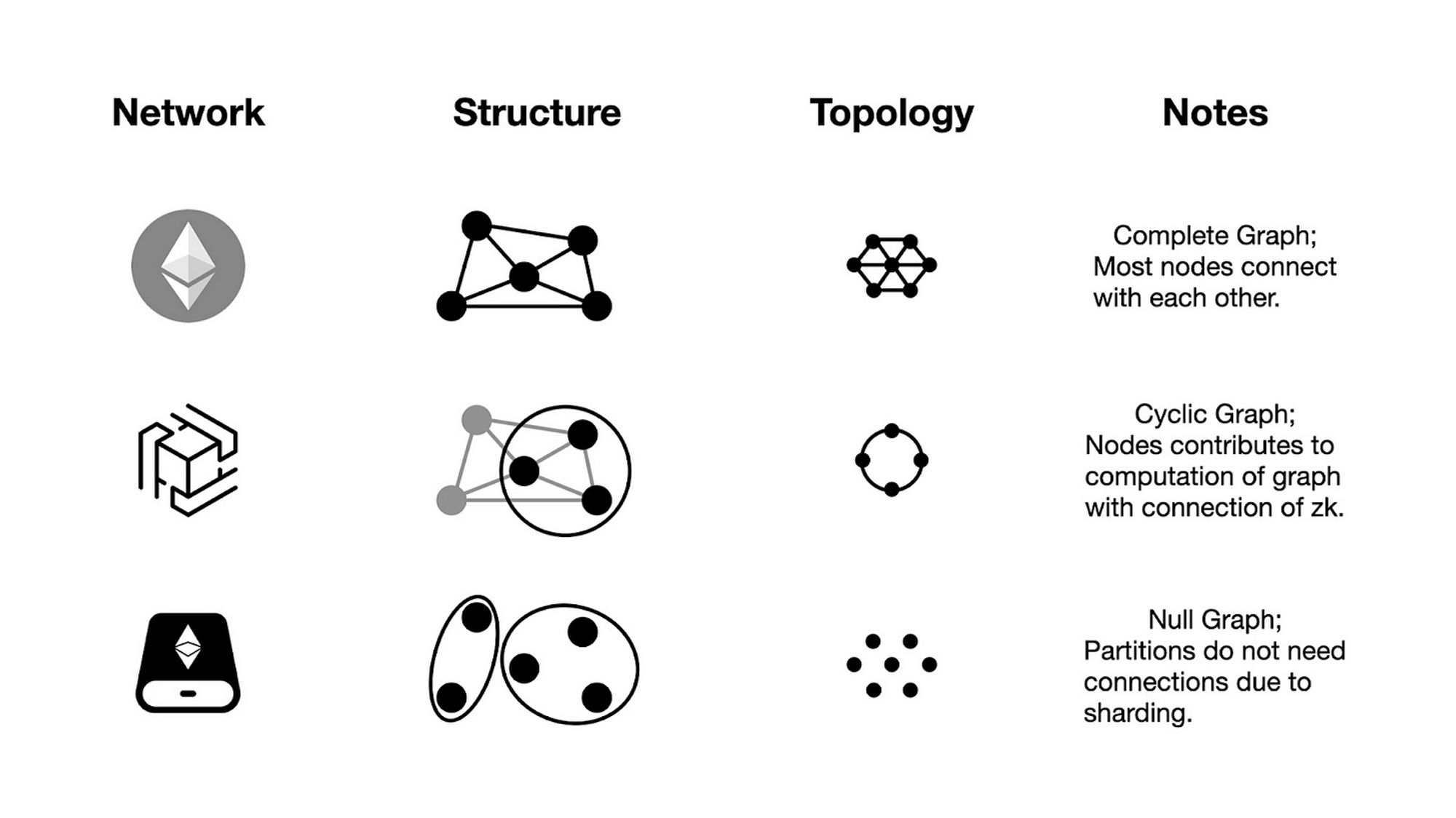
在世界超级计算机中, 共识账本区块链采用的是具有完全图形式节点的区块链形式, 而像 Hyper Oracle 的 zkOracle 网络则是一个无账本的网络, 其节点采用环形图形式, 而存储 Rollup 的网络结构则是另一种形式, 由分区形成子网络.
通过使用零知识证明作为数据总线, 将三个拓扑异构的点对点网络 (用于共识、计算和存储) 链接起来, 我们可以构建一个完全去中心化、不可阻止、无需许可且可扩展的世界超级计算机.
3. 世界超级计算机结构
与构建物理计算机类似, 我们必须将之前提到的共识网络、计算网络和存储网络组装成一个世界超级计算机.
适当选择和连接每个组件将有助于在共识分类帐、计算能力和存储容量三难问题之间实现平衡, 最终确保世界超级计算机具有去中心化、高性能和安全性.
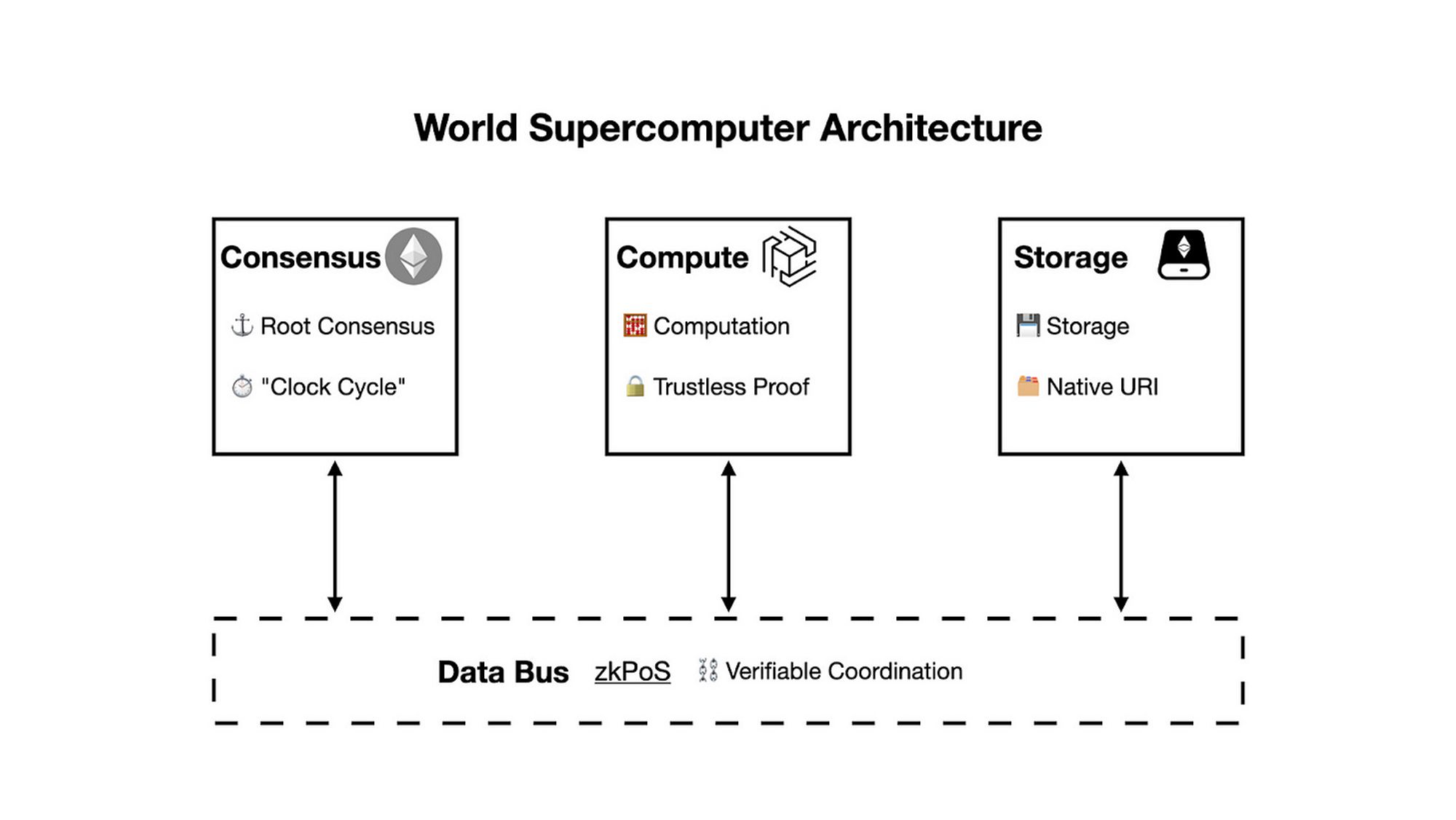
世界超级计算机的架构, 按照其功能描述, 如下所示:
具备共识、计算和存储网络的世界超级计算机网络的节点结构类似于以下示意图:
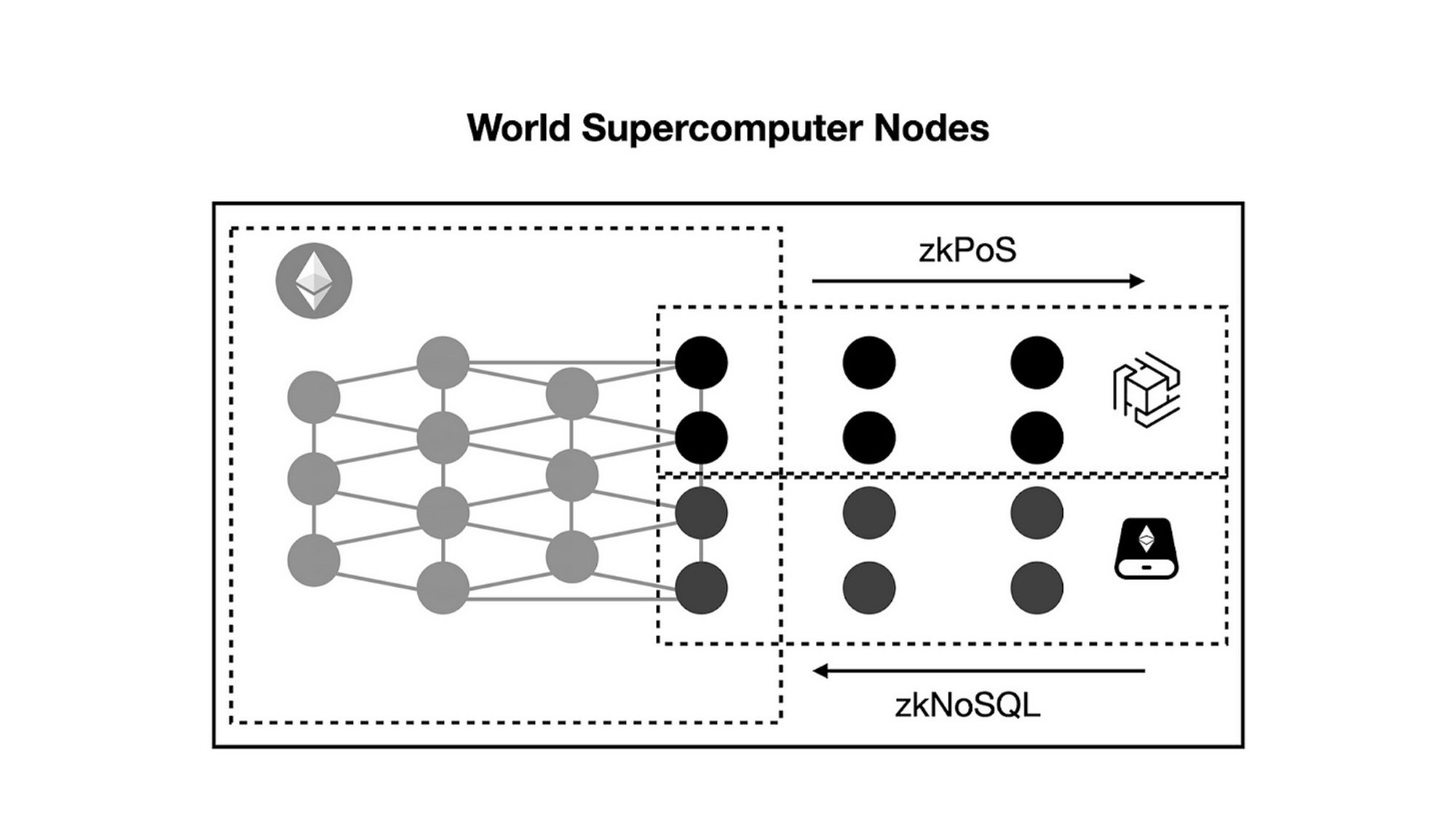
开始建立网络时, 世界超级计算机的节点将基于以太坊的去中心化基础. 具备高计算性能的节点可以加入 zkOracle 的计算网络, 用于生成通用计算或机器学习的证明; 而具备高存储容量的节点可以加入 EthStorage 的存储网络.
上述示例描述了同时运行以太坊、计算网络和存储网络的节点. 对于仅运行计算网络或存储网络的节点, 它们可以通过基于零知识证明的总线 (如 zkPoS 和 zkNoSQL) 访问以太坊的最新区块或证明存储数据的可用性, 而无需信任他人.
a) 共识: 以太坊
目前, 世界超级计算机的共识网络完全使用以太坊. 以太坊拥有强大的社会共识和网络安全, 确保了去中心化的共识.
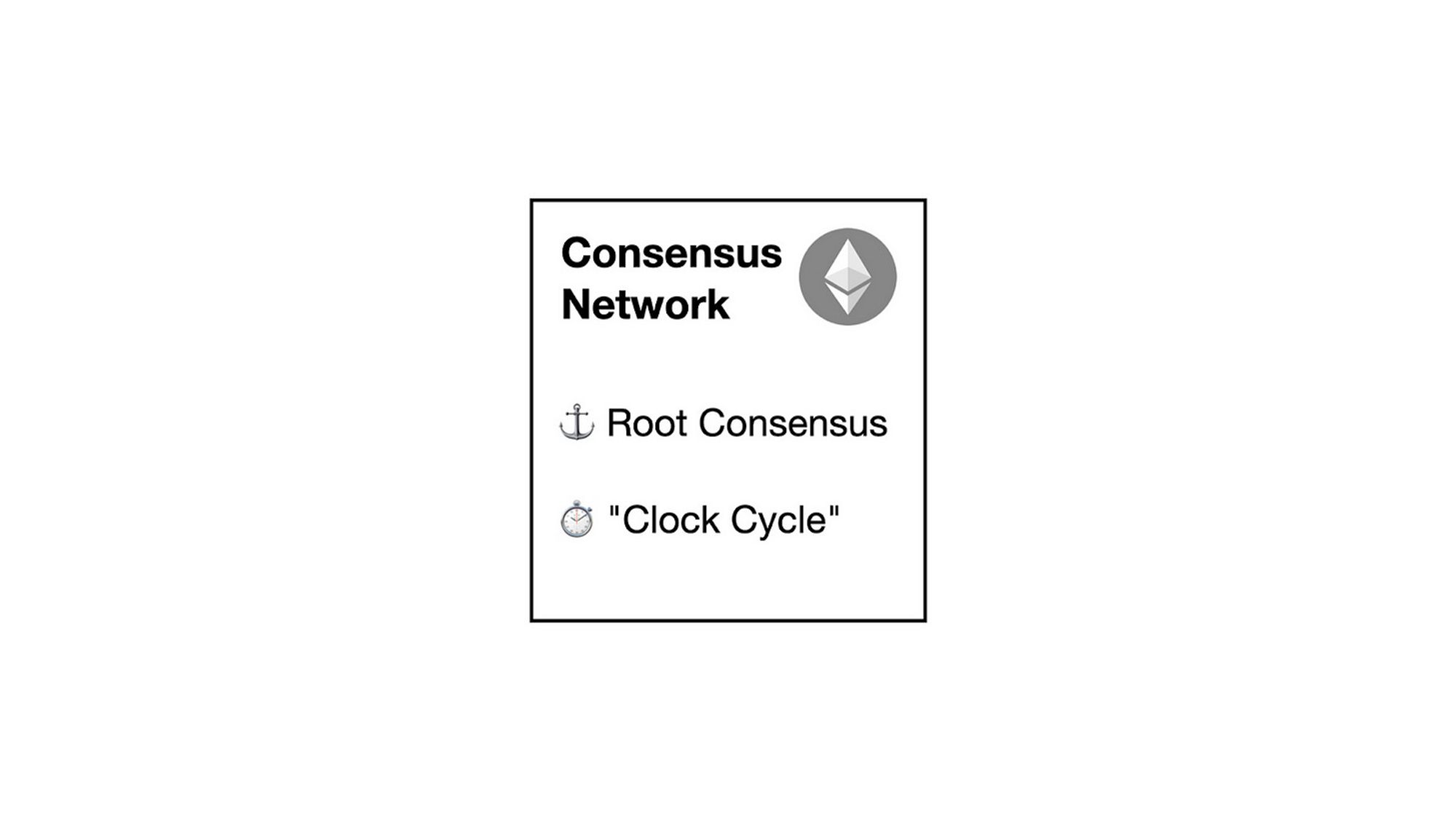
世界超级计算机建立在以共识账本为中心的架构上. 共识账本具有两个主要角色:
- 为整个系统提供共识
- 定义区块间隔的 CPU 时钟周期
与计算网络或存储网络相比, 以太坊无法同时处理大量的计算任务, 也无法存储大量的通用数据.
在世界超级计算机中, 以太坊是一个共识网络, 用于存储诸如 L2 Rollup 之类的数据可用性, 为计算网络和存储网络达成共识, 并加载关键数据, 以便计算网络可以执行进一步的链下计算.
b) 存储: 存储 Rollup
以太坊的 Proto-danksharding 和 Danksharding 本质上是扩展共识网络的方式. 为了实现世界超级计算机所需的存储容量, 我们需要一个既与以太坊兼容又能永久支持大量数据存储的解决方案.

Storage Rollups, 例如 EthStorage, 本质上是为大规模存储扩展以太坊. 此外, 由于计算资源密集型的应用程序 (如机器学习) 需要大量内存才能在物理计算机上运行, 需要注意的是以太坊的 “内存” 无法被过度扩展. 存储 Rollup 对于允许世界超级计算机运行计算密集型任务的 “Swapping” 是必要的.
此外, EthStorage 提供了 web3:// 访问协议 (ERC-4804), 类似于世界超级计算机的本地 URI 或存储资源的寻址方式.
c) 计算: zkOracle 网络
计算网络是世界超级计算机中最重要的要素, 因为它决定了整体性能. 它必须能够处理诸如预言机或机器学习等复杂计算, 并且在访问和处理数据方面应该比共识网络和存储网络更快.
zkOracle 网络是一个去中心化且最小化信任的计算网络, 能够处理任意计算. 任何正在运行的程序都会生成一个零知识证明 (ZK proof), 在使用时可以由共识 (以太坊) 或其他组件轻松验证.
Hyper Oracle 是一个 zkOracle 网络, 它由 zkWASM 和 EZKL 驱动的一组 ZK 节点组成, 来运行任何计算, 并提供 execution trace 的证明.
zkOracle 网络是一种无账本的区块链 (没有全局状态), 它遵循原始区块链 (以太坊) 的链式结构, 但作为一种没有账本的计算网络运作. zkOracle 网络不通过重新执行来保证计算的有效性, 而是通过生成证明来验证计算的可信性. 无账本的设计和专用节点的设置使得 zkOracle 网络 (如 Hyper Oracle) 能够专注于高性能和最小化信任的计算. 计算的结果直接输出到共识网络, 而不是生成新的共识.
在 zkOracle 的计算网络中, 每个计算单元或可执行单元都由一个 zkGraph 表示. 这些 zkGraph 定义了计算网络的计算和证明生成行为, 就像智能合约定义共识网络的计算一样.
I. 通用链下计算
在 zkOracle 的计算中, zkGraph 程序可以在没有外部技术栈的情况下用于两种主要用例:
- 索引 (访问区块链数据)
- 自动化 (自动执行智能合约调用)
- 任何其他链外计算
这两种场景可以满足任何智能合约开发者的中间件和基础设施需求. 这意味着作为 World Supercomputer 的开发者, 在创建完整的去中心化应用程序时, 可以经历整个端到端的去中心化开发过程, 包括在共识网络上的链上智能合约以及在计算网络上的链外计算.
II. ML/AI 计算
为了实现互联网大规模级别的采用并支持任何应用场景, 世界超级计算机需要以去中心化的方式支持机器学习计算.
通过零知识证明技术, 可以将机器学习和人工智能整合到世界超级计算机中, 并在以太坊的共识网络上进行验证, 实现真正的链上操作.
在这种情况下, zkGraph 可以与外部技术栈进行连接, 将 zkML 本身与世界超级计算机的计算网络结合起来. 这使得各种类型的 zkML 应用成为可能, 包括:
- 用户隐私保护的机器学习/人工智能
- 模型隐私保护的机器学习/人工智能
- 具有计算有效性的机器学习/人工智能
为了实现世界超级计算机的机器学习和人工智能计算能力, zkGraph 将与以下先进的 zkML 技术栈结合, 使其能够直接与共识网络和存储网络进行集成:
- EZKL: 在 zkSNARK 中进行深度学习模型和其他计算图的推理.
- Remainder: 在 Halo2 Prover 中进行快速的机器学习操作.
- circomlib-ml: 用于机器学习的 circom 电路库.
e) 数据总线: zk
现在, 我们拥有了世界超级计算机的所有基本组成部分, 但我们还需要一个最后的组件来连接它们. 我们需要一个可验证且最小化信任的数据总线, 以实现组件之间的通信和协调.
对于使用以太坊作为其共识网络的世界超级计算机来说, Hyper Oracle zkPoS 是 zk 总线的理想选择. zkPoS 是 zkOracle 的关键组成部分, 通过 ZK 验证以太坊的共识, 使得以太坊的共识可以在任何环境中传播和验证.
作为一个去中心化和最小化信任的总线, zkPoS 可以与世界超级计算机的所有组件连接, 并且由于 ZK 的存在, 其验证计算开销非常小. 只要有类似 zkPoS 的总线存在, 数据就可以在世界超级计算机内自由传输.
当以太坊的共识可以从共识层传递到总线作为世界超级计算机的初始共识数据时, zkPoS 可以通过状态/事件/交易证明来证明它. 然后, 将产生的数据传递给 zkOracle Network 的计算网络.
此外, 对于存储网络的总线, EthStorage 正在开发 zkNoSQL, 以实现数据可用性的证明, 从而使其他网络能够快速验证 BLOBs 具有足够的副本.
f) 另一个案例: 比特币作为共识网络
与许多 Layer2 Sovereign Rollup一样, 比特币等去中心化网络也可以作为支撑世界超级计算机的共识网络.
为了支持这样的世界超级计算机, 我们需要替换 zkPoS 总线, 因为比特币是基于工作量证明机制的区块链网络.
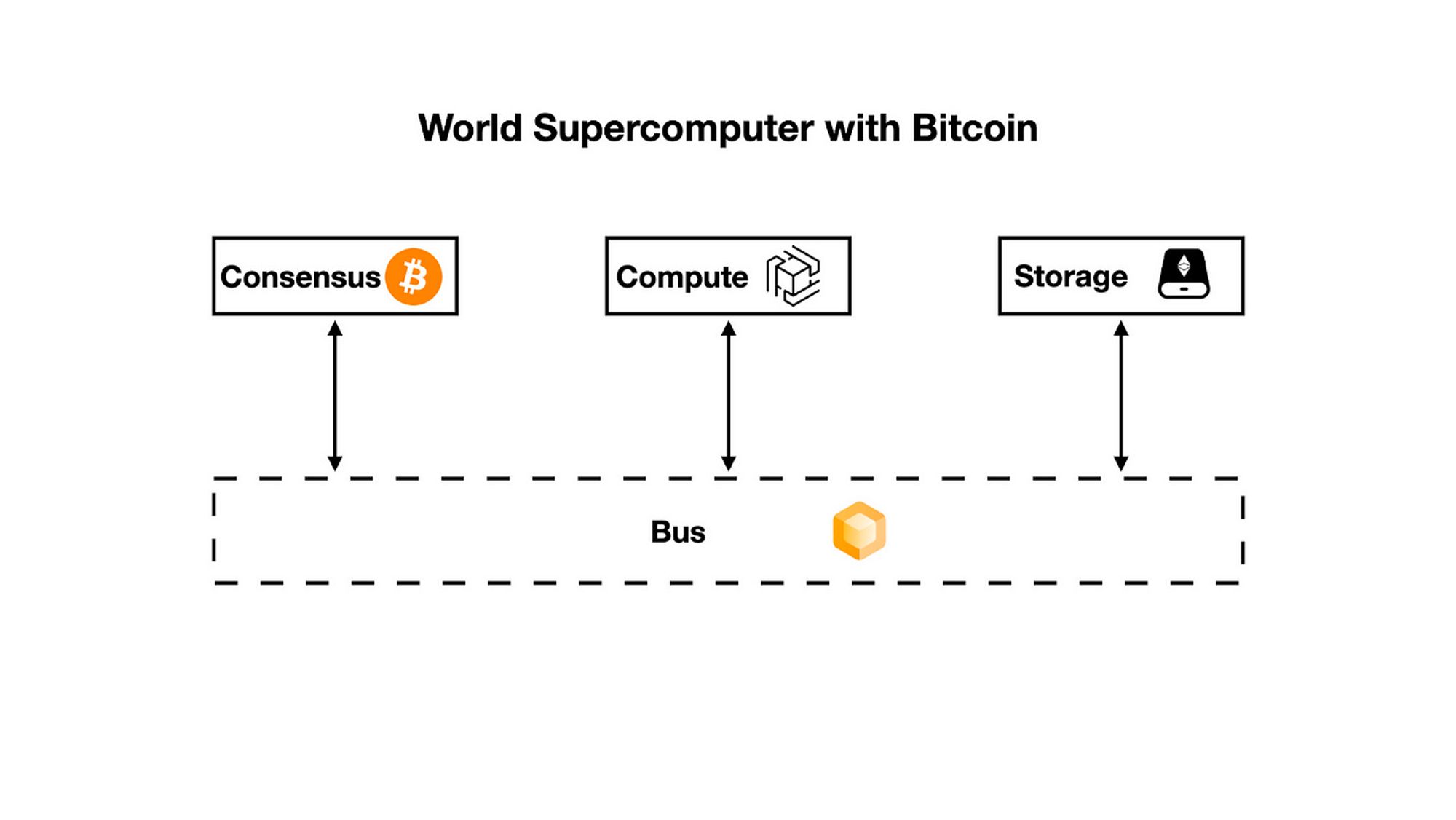
我们可以使用 ZeroSync 来实现基于比特币的世界超级计算机的零知识证明总线. ZeroSync 类似于 "zkPoW", 它通过零知识证明将比特币的共识进行同步, 使得任何计算环境都可以在毫秒级内验证和获取最新的比特币状态.
g) 工作流程
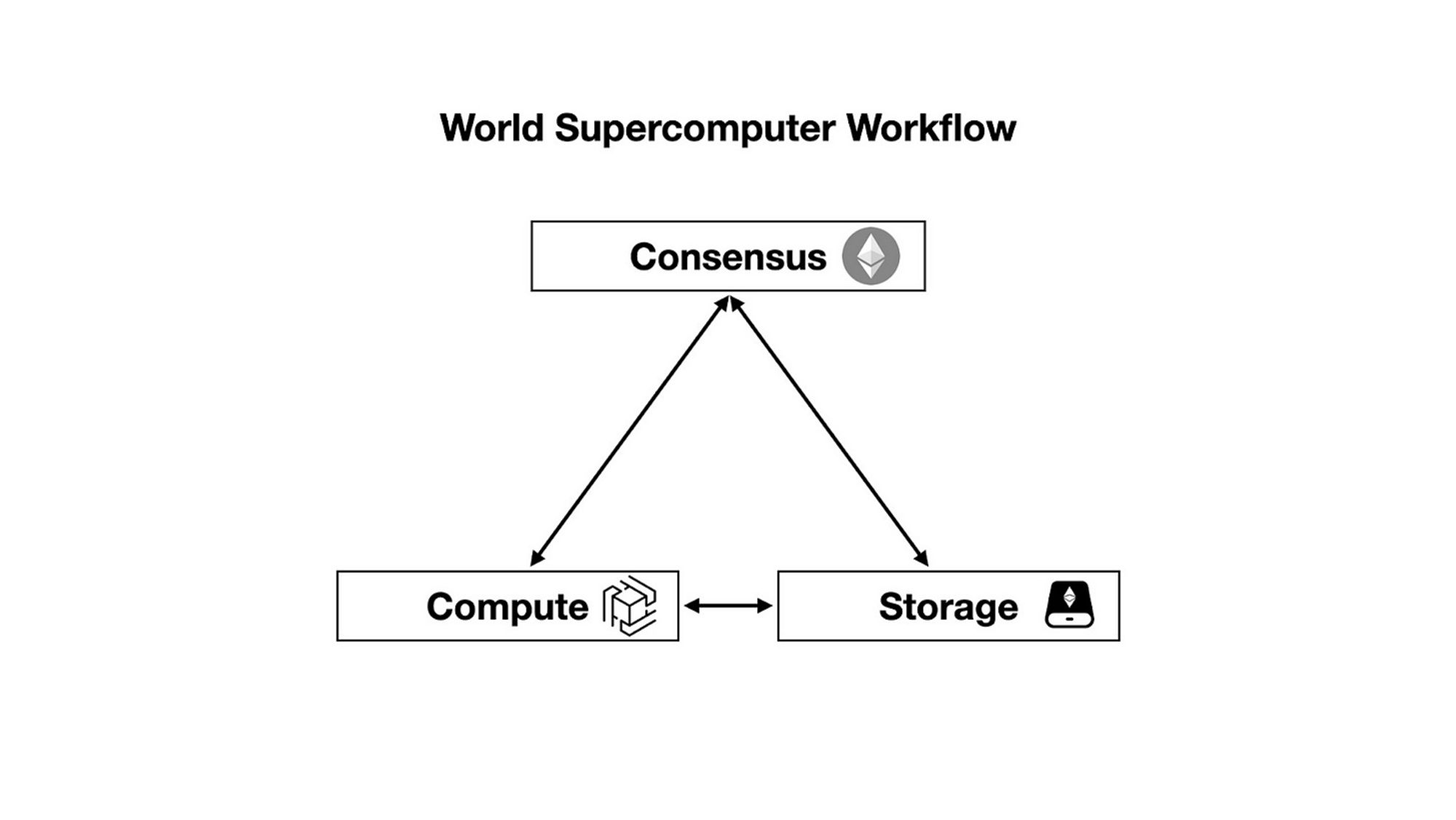
以下是基于以太坊的世界超级计算机中的交易过程概述, 分解为以下步骤:
- 共识: 使用以太坊处理和达成交易共识.
- 计算: zkOracle Network 通过快速验证由充当总线的 zkPoS 传递的证明和共识数据, 执行相关的链下计算 (由从 EthStorage 加载的 zkGraph 所定义).
- 共识: 在某些情况下, 例如自动化和机器学习, 计算网络将通过证明将数据和交易返回给以太坊或 EthStorage.
- 存储: 为了存储来自以太坊的大量数据 (例如 NFT 元数据), zkPoS 充当以太坊智能合约和 EthStorage 之间的传递者.
在整个过程中, 总线在连接每个步骤中扮演着至关重要的角色:
- 当共识数据从以太坊传递到 zkOracle Network 的计算或 EthStorage 的存储时, zkPoS 和状态/事件/交易证明生成证明, 接收方可以快速验证以获取精确的数据, 例如相应的交易.
- 当 zkOracle Network 需要从存储中加载计算所需的数据时, 它使用 zkPoS 从共识网络中访问存储上的数据地址, 然后使用 zkNoSQL 从存储中获取实际数据.
- 当来自 zkOracle Network 或以太坊的数据需要以最终输出形式显示时, zkPoS 为客户端 (例如浏览器) 生成证明, 以便快速验证.
4. 结论
比特币为创建世界计算机 v0 打下了坚实的基础, 成功构建了 "世界账本". 后来, 以太坊通过引入更加可编程的智能合约机制, 有效地展示了 "世界计算机 "的范式. 随着去中心化的目的、密码学固有的不可信任性、MEV 的自然经济激励、大规模采用的动力、ZK 技术的潜力, 以及最重要的是对包括机器学习在内的去中心化通用计算的需求, 世界超级计算机的出现已经成为一种必然.
我们提出的解决方案将通过连接具有零知识证明的拓扑异构 P2P 网络来建立世界超级计算机. 作为共识账本, 以太坊将提供底层共识, 并将区块间隔作为整个系统的时钟周期. 作为存储网络, Storage rollup 将存储大量的数据, 并提供一个 URI 标准来访问这些数据. 作为计算网络, zkOracle 网络将运行资源密集型的计算, 并生成可验证的计算证明. 作为数据总线, 零知识证明技术将连接各种组件并允许数据和共识被链接和验证.